分组函数(多行处理函数)
多行处理函数特点:输入多行,输出结果是一行 select后只能跟:参加分组的字段,以及分组函数,其他的一律不能跟
所有分组函数自动忽略NULL!!!!!!!!!!!
| Count | 计数 |
|---|---|
| Sum | 求和 |
| Avg | 平均值 |
| max | 最大值 |
| Min | 最小值 |
所有的分组函数都是对‘某一组数据’进行操作的。
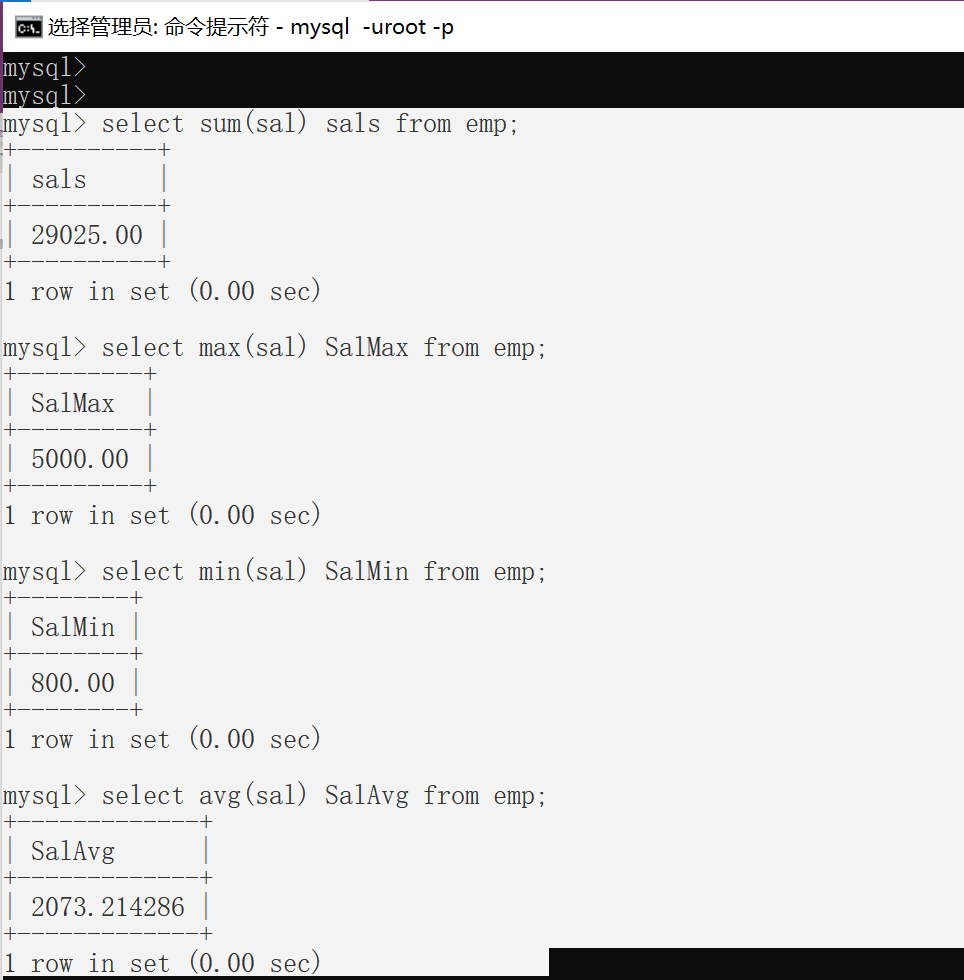
- 找出工资总和
- 找出最高工资
- 找出最低工资
- 找出平均工资
找出总人数 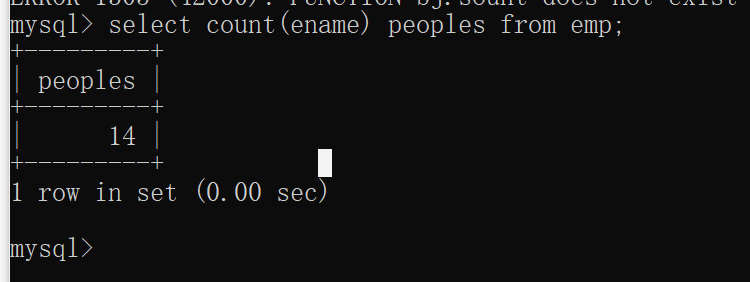
分组函数自动忽略NULL。
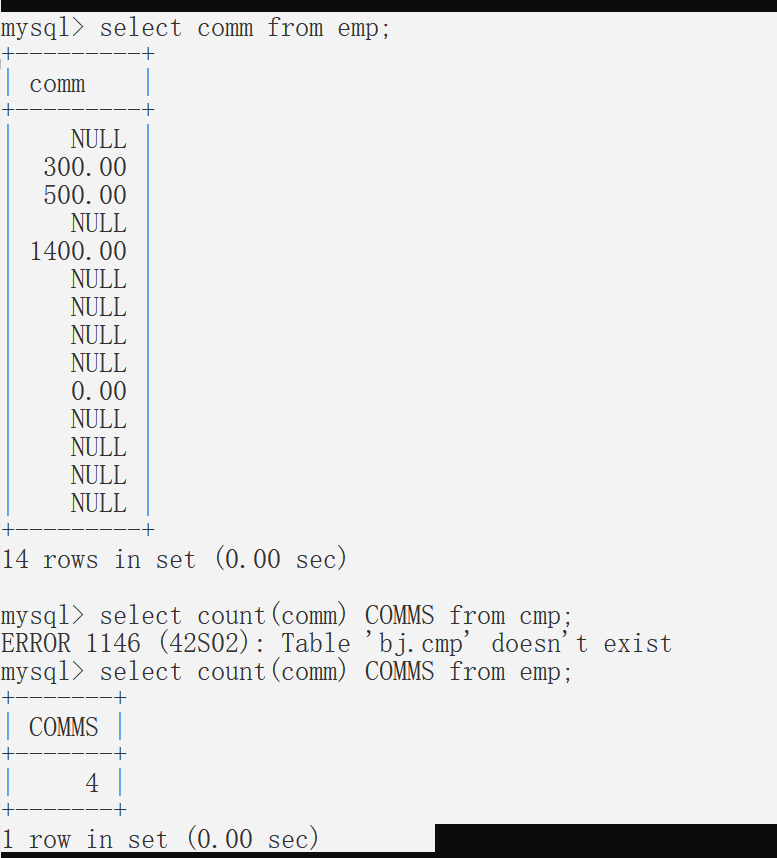
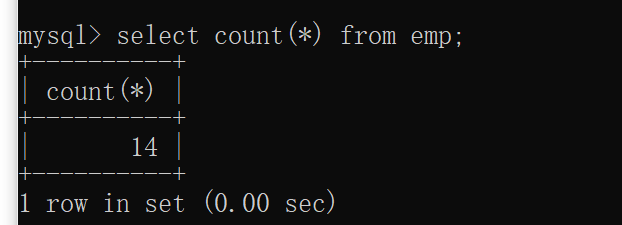
Count * 和count(具体字段)的区别
Count * :统计的一定是这个表中数据的总条数【和某个字段无关】 Count (具体字段):一定是将NULL排除在外再进行统计的
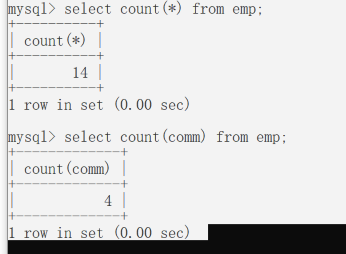
分组函数的组合使用:

Group by 和where的执行顺序
找出比平均工资高的员工;
mysql> select avg((sal + comm)*12) from emp;
+----------------------+
| avg((sal + comm)*12) |
+----------------------+
| 23400.000000 |
+----------------------+
1 row in set (0.00 sec)
mysql> select ename ,sal from emp where sal>avg((sal+comm)*12);
ERROR 1111 (HY000): Invalid use of group function这么写似乎没有问题,但是语法上会出错【无效使用了分组函数】
因为SQL语句中有一个语法规则,分组函数不能直接使用在where子句中。
为什么不能?
分组函数 是在分完组之后( group by函数)后再执行的,即使没有分组,那整个表也会自成一组; 在where之后才会进行分组(group by),分组后才能使用分组函数 所以,没有分组不能使用分组函数 字段执行顺序
最终解决:使用子查询;
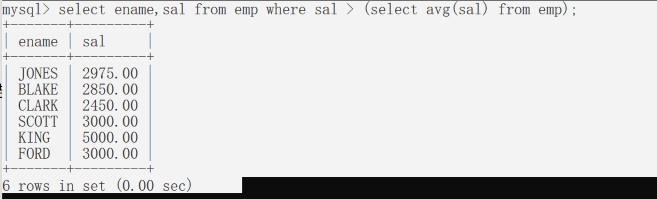
Group by和 having
Group by:按照某个字段或者某些字段进行分组 having:having 是对分组之后数据进行再次过滤
Having不能单独使用,必须配合Group by
优化策略:where和having优先选择where,where是在完成不了,再使用having
语法格式:
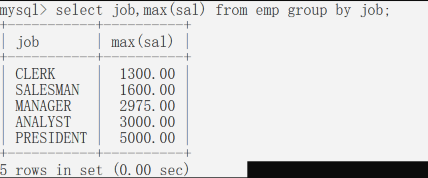
Select 要找的东西(一般是分组函数或字段名) From 表名 Group by 分组字段先按照分组字段进行分组,再求最大值【分组函数永远在group by之后执行】
分组函数一般和group by联合使用,这也是为什么他会被称为分组函数的原因。 并且任何一个分组函数(count 、sum、avg、max、min)都是在group by函数执行结束后才会执行的,当一个SQL语句中没有group by语句时,整个表自成一组。
找出每个岗位的最高薪资;
单行处理函数
输入一行,输出一行 If null()就是单行处理函数
单行处理函数处理一条返回一条,所以通常是多条返回的,而单行无论是多少行处理,返回的只会是一行
NULL的运算处理
计算每个员工的年薪;
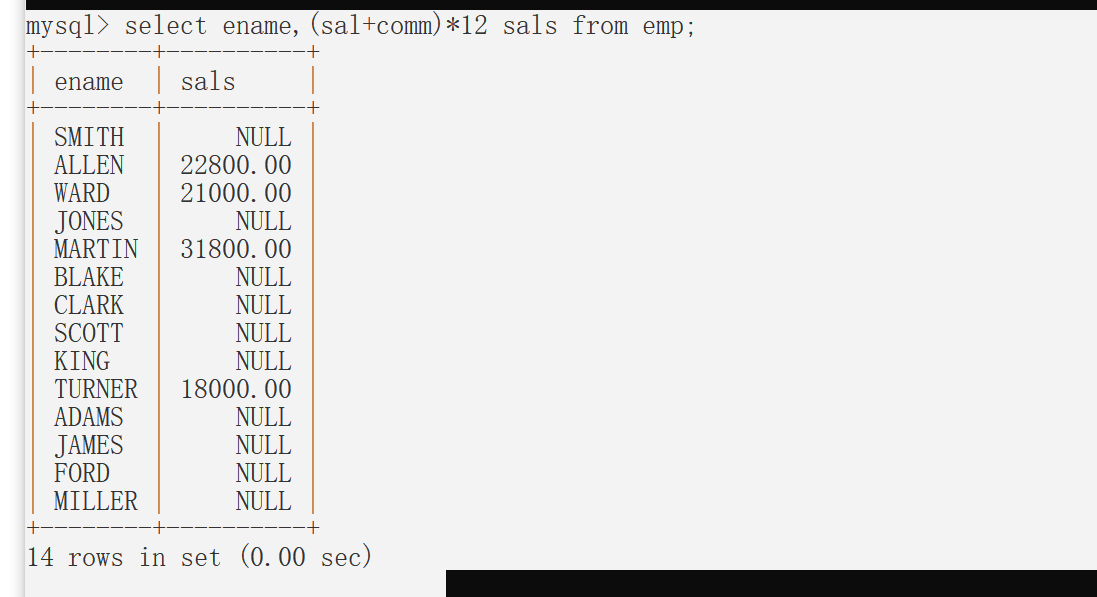
有 NULL 参加的运算,结果是 NULL 数据库规定:在一个式子中,无论最后结果如何,只要式子中有一个元素是NULL,那么结果一定是 NULL
解决方式: if null() 空处理函数 语法:if null(可能是NULL的数据 , 被当作什处理)
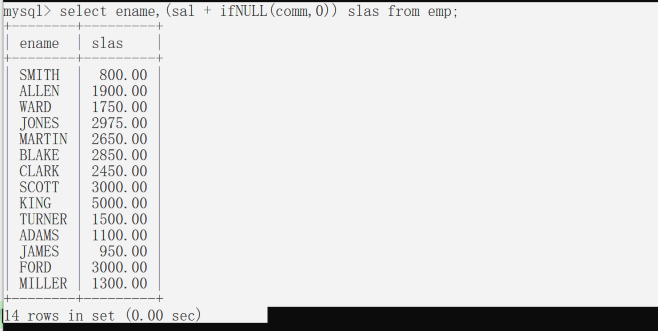
当sal是NULL时,将NULL当0处理,并进行计算
多行处理函数如何处理NULL
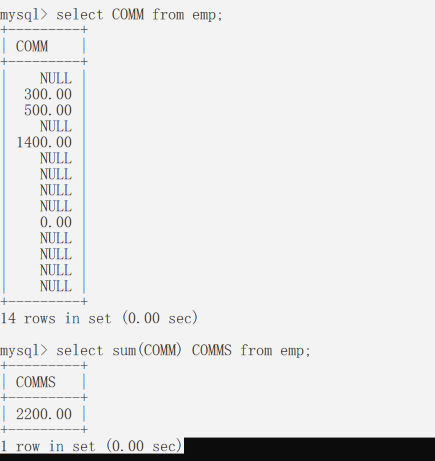
因为运算中有NULL返回值一定NULL,但是多行处理时,返回结果并不是NULL。 故,多行处理函数会自动忽略NULL
多字段分组查询
当一个语句使用 group by 语句的话,select 后面只能跟分组函数和参与分组字段。
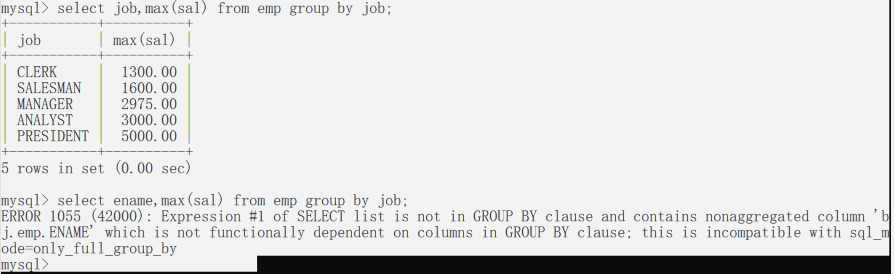
在其他的数据库中违反这个可能有数据,但是没有意义
当多个字段联合分组时,将两个字段关键字使用逗号进行间隔,这样两个字段会进行联合分组。 找出不同部门(dtptno)每个工作岗位(job)的最高薪资; 找出不同部门每个工作岗位的最高薪资;
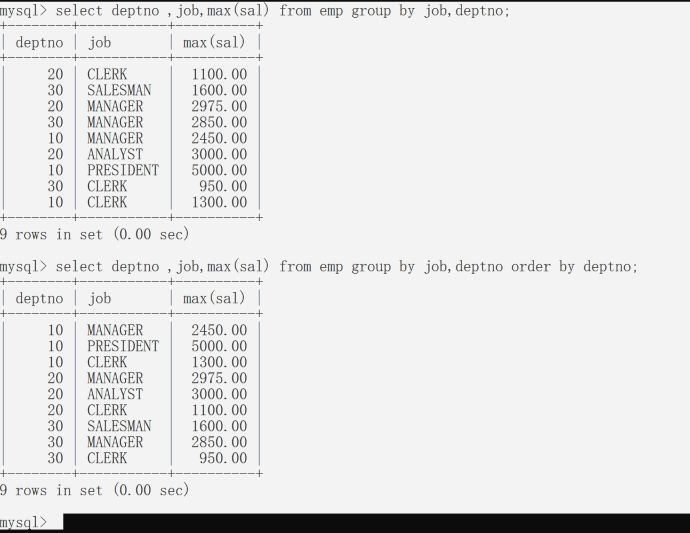
Having
找出每个部门的最高薪资,要求显示薪资大于2500的数据;
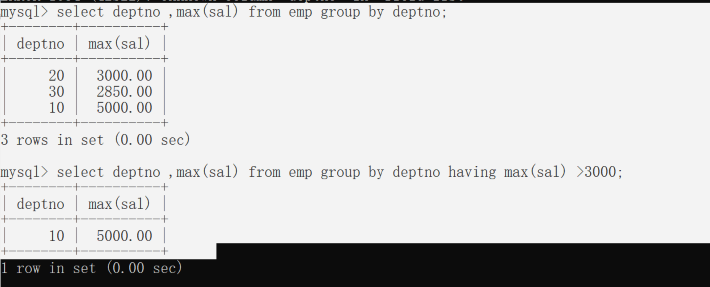 先找出数据中薪资最高的,再将薪资大于 3000 的进行呈现,但是这种方式有运算完舍弃的数据,所以效率较低,不建议。
先找出数据中薪资最高的,再将薪资大于 3000 的进行呈现,但是这种方式有运算完舍弃的数据,所以效率较低,不建议。

在这里使用 where,进行筛选后再进行排序,效率更高【能使用where做的就是用where】
找出每个部门的平均薪资,要求平均薪资大于2000的;
各个关键字执行顺序
Select
...
Form
...
Where
...
Group by
...
Having
...
Order by
...先执行 from,表中数据导入; 再执行 where,经过条件过滤; 再执行 group by,将数据分组; 再执行 having,进行过滤; 再执行 select,将数据查出来; 最后执行 order by,进行排序输出;
TIP
在where之后才会进行分组(group by),分组后才能使用分组函数
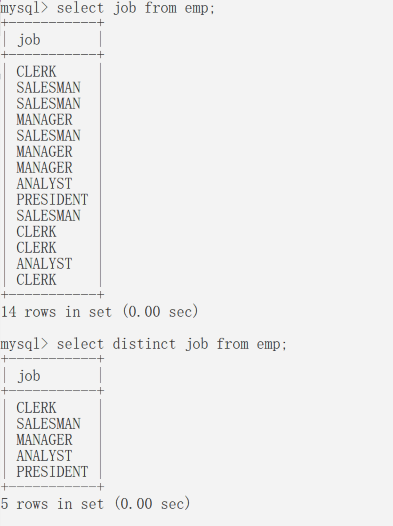
查询结果的去重
Distinct —> 有差距的,有差异的
TIP
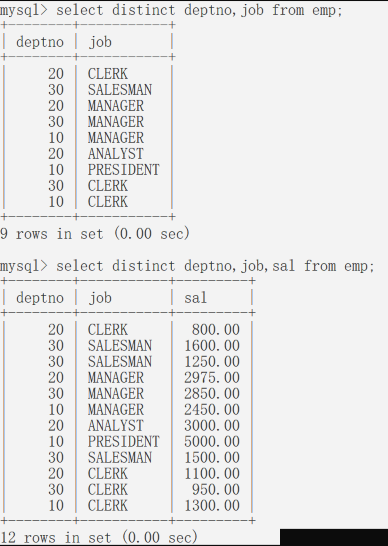
distinct 只能出现在所有字段的最前方
这个关键字可以去除重复的记录
distinct出现在字段最前方指的是字段联合去重
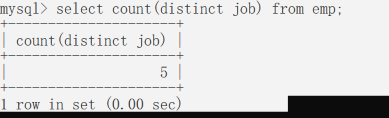
计算岗位数量